
Стеганография читаем и размещаем скрытые данные из PNG
Зарегистрируйся в Академии Кракен (Kraken Academy) и учись на практике: стенды, модули и реальные скиллы.
В этой статье я опишу как я работал с инструментами стеганографии. Не могу обещать здесь какой-то научной точности в описании каждого из них, по этому не воспринимайте это как "--help", это больше, обычные примеры применения с рассуждениями автора.
Как-то я одновременно в двух телеграм каналах наткнулся на публикации от разных авторов на тему применения инструментов стеганографии. Статьи были о разных инструментах, какая-то давала меньше информации, какая-то была чуть более развернутой. Но обе они вызвали у меня интерес. Я решил посмотреть, какие есть способы спрятать информацию в картинке, чтобы незнающие этого, не смогли её увидеть.
Я постарался "потрогать" несколько способов сокрытия текста в изображении и его обнаружении. Так что пройдём путь и в одну и в другую сторону.
А так же, я хотел уточнить, что я использую в рамках этой статьи определенный пул инструментов. Я не говорю что это единственно верный выбор инструментов. Вы в праве использовать что захотите. Скорее всего, это будет эффективнее, чем то, что использовал я.
Так же, небольшое предисловие постфактум. После публикации статьи, я решил проверить, возможно ли будет скачать изображения для проверки внесённых мною изменений. Как оказалось, они почему-то стираются. Так что, если у кого-то из читающих будет желание попробовать найти срытый текст, им придётся самостоятельно его прятать.
Обрезаем текст (но так чтобы было ввидно)
Одна из самых простых техник, как мне кажется, это спрятать текст на картинке, после чего, обрезать его, но оставить возможность вернуть прежний размер. После возвращения прежнего размера я смогу увидеть текст.
Нашим подопытным почти для всех методик сокрытия текста на эту статью будет вот эта милаха.

Для того, чтобы было что прятать, надо что-то добавить. При помощи инструмента convert добавлю моему коту текст:
convert Cute_cat.png -gravity south -pointsize 60 -fill black -annotate +0+0 "У кота лапки" Cute_cat_text.png
Чуть подробнее о команде. Вдруг кому-нибудь это пригодится:
Cute_cat.png - Исходное изображение.
-gravity south - Якорь, обозначающий расположение текста на картинке (юг, в данном случае). Может быть так же (northwest, north, northeast, west, center, east, southwest, south, southeast).
-pointsize 60 - Размер шрифта.
-fill black - Цвет текста.
-annotate +0+0 "У кота лапки" - Смещение относительно якоря на указанное количество пикселей. И сам текст.
Cute_cat_text.png - Конечный файл.
По итогу у меня вышла такая картинка:

Теперь попробую спрятать текст. С одной стороны, в чём смысл прятать такую ерунду? Но, представим что вместо текста "у кота лапки" кто-то вставил какой-нибудь ключ от криптокошелёк, или координаты хранилища леденцов? Было бы прикольно иметь возможность узнать такие вещи, верно? Но для начала их надо спрятать.
Если попытаться просто кропнуть изображение, вас, как и меня, ждёт неприятный сюрприз. Оно просто обрежется, и обратно вы его восстановить не сможете. При попытке вернуть прошлый размер через редактор изображений и через инструмент для работы с бинарными файлами, у меня получилось это:

Это только в тут на месте обрезки что-то серое. По факту, если закинуть сюда обрезанное кропом и восстановленное изображение, вместо серого цвета будет пустота, так как это png (восстановленное место будет просто прозрачным и на том месте, где что-то должно быть, просто будет альфа слой).
Так вот, чтобы правильно обрезать текст, имея возможность его восстановить, мне нужно залезть в бинарник изображения. Не важно через что это будете делать вы, если захотите повторить мой путь, главное, чтобы при выводе, у вас отображались полуслова (то есть по два байта в одном блоке). Так проще для понимая, как по мне, и всё не сливается в одну кашу. Так вот, я пользуюсь инструментом radare2, но вообще, существует множество различных решений под Windows и linux. Когда я проворачивал этот же трюк на Windows, использовал HxD, тоже очень удобная штука.
Так вот, запускаю radare2 с моим котиком, после чего хочу посмотреть первые 64 байта данного документа:
radare2 Cute_cat_text_cuting.png
px 64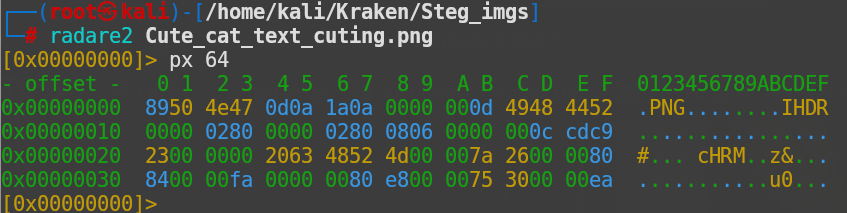
Какая-то мешанина символов и цифр, но благодаря аннотации справа, можно кое-что понять, а благодаря гуглу, узнать. Как видно, первый байт (89) указанный в шестнадцатеричной системе, это какая-то точка. Но по факту, это символ с кодировкой 89 в шестнадцатеричной системе и 137 в десятичной, который обозначает начало изображения, так как символа с кодом 137 нет в ASCII и при попытке прочитать файл. Редактор не примет его за текстовый. А так как дальше идут байты, обозначающие формат изображения (50, 4e, 47) что в кодировке UTF-8 обозначает P, N, G, это возможно. Далее, идут разрывы и переносы строк, затем байт обозначающий конец бинарного файла и снова перенос строки. А после, блок IHDR в котором находится так нужная нам в данный момент информация о размере файла. Да, всё верно. Не получилось кропнуть при помощи редактора картинок, будем кропать через бинарный код.
В чём суть такого подхода? Когда я обрезал изображение в редакторе, все байты этого изображения, которые подпадали под обрезание, удалялись безвозвратно. Я буквально говорил редактору: удали информацию с 10000 по 10050 строку. А если я изменю размер в блоке IHDR, я просто не буду показывать часть изображения, а не удалю её окончательно. Конечно, всё не так просто, но об этом по порядку.
Давайте ещё раз посмотрим на вывод первых 64 байт информации:

Как я писал выше, меня интересует блок IHDR, а это всё, что располагается после 8 байт (4948 4452) Давайте посмотрим что там имеется. Первые непустые полуслова это 0208 и 0208, соответственно. Переведя их из 16-тиричной системы получаю значения 640 и 640. Всё ясно, это размер изображения в пикселях. Это то мне и понадобится, но давайте посмотрим что там ещё имеется.

Байт "08" - это глубина цветового канала (тип, сколько цветов используем, кажется так. В нашем случае, это обычный RGB).
Байт "06" - определяет тип цвета. В зависимости от значения в этом байте - к изображению могут применяться разные типы цвета (В нашем случае это 6: Truecolor + alpha (RGBA), каналы: R, G, B, A).
Байт "00" (тот, что я бардовым подсветил) - метод сжатия. Для PNG должен быть 0, по-правильному. Если не 0 - значит ошибка формата,
Байт "00" (который сразу после бордового - подчеркнут светло зеленым) - методом фильтрации. Так же должен быть нулём.
Байт "00" (подчеркнут оранжевым) - метод интерлейса. Как рисовать изображение при его погрузке. Тут стоит 0, так как интерлейсинг отключен. Может быть значение 1.
Эти 13 байт (8 байт размера + 5 байт остальных данных) являются критическими для файла. Если вы что-то измените в них, картинка может повредиться и не открыться. И для проверки того, что указанные байты не повреждены и не изменены, существует чанк контрольной суммы (CRC).

В моем бинарнике это значение равно 0ccdc923 (выделил его розовым). Очень важно, если что-то из этих тринадцати байт изменить, нужно менять и эти 4 байта. Они вычисляются как сумма предыдущих 13-ти байт + 4 байта типа данных(IHDR). Давайте покажу на примере как это происходит.
И так, как я и говорил, мне надо обрезать изображение так, чтобы кропнутая его часть оставалась доступной для просмотра при определенных действиях. Для этого, я хочу изменить высоту изображения с 640 пикселей, на 500, то есть, изменить значение 22-23 байтов с 0280 на 01f4 и в последовее обязательно изменить контрольную сумму.

Я выделил области, которые изменил. Вы, наверное, спросите "Вау, а как ты так просто посчитал новую контрольную сумму?", а я отвечу "Зачем мне делать работу, которую за меня уже сделали?". Сейчас объясню. В первую очередь, я изменил 2 байта, отвечающие за высоту изображения. После этого, изменения вступили в силу и изображение уже стало битым, так как контрольная сумма теперь не совпадает с той, что прописана в бинарнике. Во втором окне, я открываю инструмент
pngcheck Cute_cat_text_cuting.png для проверки PNG изображения. И вот что он мне показал:

В выводе мне выдало "Ошибка контрольной суммы в чанке IHDR (вычисленное значение ad969c69 (зеленый) а ожидалось 0ccdc923 (красный))". Понимаете к чему клоню? Мне просто надо взять это вычисленное значение и подставить в байты с 30-го по 33-й, проще простого.
Теперь, когда изменил размер картинки, и заменил контрольную сумму, я получаю такой результат:

Красивое обрезанное изображение. Вы можете скачать его, и ради интереса проверить. Вся информация о скрытых байтах в нем до сих пор сохранена и доступна для просмотра. При этом, даже exiftool не покажет "истинный" размер изображения.
А для того, чтобы увидеть текст, необходимо проделать все действия в обратном порядке. Ну, то есть, вернуть прежний размер, или, вернуть любой размер, запустить pngcheck Cute_cat_text_cuting.png, узнать какая контрольная сумма должна при этом быть, произвести её замену и получить изображение с текстом. Профит!
Скрываем текст в бинарном файле
Так, я только что (почти) безнаказанно залезал в бинарный файл и менял там данные, чтобы что-то скрыть. Банальный вопрос, но можно ли спрятать что-то в этом самом бинарнике? Можно! Любая текстовая информация хранится в чанке (или блоке, что то же самое) tEXt (или чанках, их может быть много в одном сообщении). То есть, я могу либо внести данные в существующий чанк, либо создать новый и внести данные туда.
Для начала, надо понять как вообще устроены чанки. Они представляют собой 4 блока, которые содержат определенную информацию:
- Блок длины - Тут указывается длина данных, а именно сколько байт составляет длина всего чанка. Состоит из 4 байт.
- Блок типа данных - В нем указывается тип чанка (tEXt IHDR, и т.д.) Состоит из 4 байт.
- Блок данных - Тут мы кодируем сообщение. Например, в примере с обрезанием тут сохранялась информация о размере изображения, глубине цвета, метод сжатия и так далее. Нет фиксированного количества байт.
- Блок контрольной суммы - Тут мы указываем (прошу прощения за тавтологию) контрольную сумму. Считается как сумма блока типа и блока данных. Состоит так же из 4 байт.
И так, зная это, мне нужно составить чанк. Начну со второго и третьего блока, так как тут всё понятно, это тип tEXt и сообщение. Для того чтобы залить это в бинарник, надо перевести текст в ASCII кодировку. Это можно сделать командой в терминале:
printf 'tEXtComment\0У кота есть лапки' | xxd -p
На выходе получаю тип чанка вместе с сообщением в шестнадцатеричном виде.

Окей, сообщение есть, надо посчитать его длину. Тут, всё ещё проще, я действую руками, но если хотите, можно автоматизировать простым питоновским скриптом. Считаю количество символов: "Comment" - 7 символов. "Укотаестьлапки" - 14 символов. "\0 - 4 символа (знак разделения и три пробела). На каждый латинский символ и символ разделения у нас требуется по одному байту, на кириллицу уходит по 2 байта, так как её нужно кодировать в UTF-8, 7+4+14*2 = 39. Это длина сообщения в байтах, её надо запомнить. Как можно заметить, я не посчитал блок tEXt.Это я сделал для того, чтобы разделить в своем и вашем понимании эти части.
Так, получается, блок текста у меня будет 39 байт, длина остальных трёх блоков мне известна, она по 4 байта. Тогда, общая длина чанка составит 51 байт, что в 16-тиричной системе будет записано как 33. Вот и готов первый блок. Осталось только контрольную сумму посчитать. Помните, в прошлый раз я смотрел контрольную сумму через pngcheck? В этот раз, так не прокатит и придётся идти по нормальному пути. Посчитать CRC сумму можно так:
printf '74455874436f6d6d656e7400d0a320d0bad0bed182d0b020d0b5d181d182d18c20d0bbd0b0d0bfd0bad0b8' \
| xxd -r -p \
| cksum printf '74455874436f6d6d656e7400d0a320d0bad0bed182d0b020d0b5d181d182d18c20d0bbd0b0d0bfd0bad0b8' - В стандартный вывод я передал два склеенных друг с другом блока tEXt и сообщение.[
| xxd -r -p Преобразую данные из их шестнадцатеричного представления, опцией -p. То есть, я говорю что на вход идёт обычная строка байт без привязки к адресам, а -r это реверс. То есть надо преобразовать из текста в реальные байты. То есть из этой мешанины символов я получу тот текст, что закодировал (если запустить без последней части).
| cksum - Считает контрольную сумму CRC-32 для полученных байт. И выдает ответ в формате [Контрольная сумма] [длина сообщения].

Получаю CRC 3039574080 и длину сообщения 43 байта (что даже совпадает с результатами т.к. 39+4=43).
Сформирую итоговый чанк:
Длина чанка: 0033
Тип чанка: 74455874
Данные в чанке: 436f6d6d656e7400d0a320d0bad0bed182d0b020d0b5d181d182d18c20d0bbd0b0d0bfd0bad0b8
CRC чанка: 6a6e29f4
Получаем: 003374455874436f6d6d656e7400d0a320d0bad0bed182d0b020d0b5d181d182d18c20d0bbd0b0d0bfd0bad0b86a6e29f4
Дело за малым, вставить это в мой бинарник png картинки. Это можно сделать в любое место картинки, но не нарушая её целостности, то есть посреди другого чанка запихать новый не получится. Лучше всго это сделать сразу после какого-нибудь из них, либо, в конце файла. Я покажу как вставить блок данных в конец файла, но если вы захотите повторить, можете по гуглить редакторы, которые позволяют выполнять операцию вставки не затирая блок, стоящий после добавляемого значения.
Первым делом, я расширяю существующий файл на значение длины нашего чанка, а именно на 51 байт. Использую утилиту для побайтового кодирования dd:
dd if=/dev/zero bs=1 count=51 >> Cute_cat_text_chunk.png
if=/dev/zero - if это "input file" а именно источник данных. В качестве источника беру специальное устройство, которое выдаёт бесконечный поток нулевых байтов (0х00).
bs=1 - размер одного блока 1 байт.
count=51 - количество блоков 51. Ну как я выше и писал о размере чанка
>> Cute_cat_text_chunk.png - заливаем эти нулевые байты в конец файла.
Если до этого у вас был открыт файл в r2, его нужно будет закрыть и открыть заново. После этого, я перехожу в конец файла и двигаюсь обратно на 51 байт. Думаю, очевидно почему я так делаю. И после этого, записываю мой чанк в бинарник по адресу на который перешёл ранее. Всё это выглядит так:
s $s-51
wx 003374455874436f6d6d656e7400d0a320d0bad0bed182d0b020d0b5d181d182d18c20d0bbd0b0d0bfd0bad0b86a6e29f4
px 64 
Чанк записан и цел. Мы ничего не перезаписали. Файл при этом, не битый и открывается нормально. Вот и он:

Если будет желание поэксперементировать, можете скачать его и проверить. Все добавленные байты на месте.
Окей, но как мне проверить PNG на наличие таких возможных скрытых посланий? Всё просто. В том же hex редакторе я просто ищу чанки с типом tEXt / tEXt в r2 выдаст все адреса в которых записан искомый текст. В моем случае результат будет только один:

Ага, видим что по адресу 0x00018de8 имеется чанк tEXt, а значит там что-то лежит. Надо как-то это что-то посмотреть, верно? Поскольку в моём тексте зашифрована кириллица, просто так в правой части она не отобразится, так как большинство hex редакторов работают одновременно с одной кодировкой ASCII и не могут интуитивно распознать что в чанке закодировано ещё и что-то с UTF-8. По этому, надо отдельно вытаскивать этот блок и декодировать его. В r2 это делается очень муторно, по этому, я воспользуюсь внешними инструментами:
r2 -qc 'izz' Cute_cat_text_chunk.png | grep -n '0x00018de'
Давайте вкратце расскажу что тут происходит
r2 -qc 'izz' Cute_cat_text_chunk.png - запускаю hex редактор r2 с флагами -qcкоторые соответственно запускают тихий режим (-q) и просят выполнить команду в кавычках и выйти (-с 'izz'). Запускаю, соответственно, для файла Cute_cat_text_chunk.png
grep -n '0x00018de' - Ищу в выводе izz строку с адресом 0x00018de, при этом, указывая номер строки в выводе (для этого использую флаг -n). Возможно, вы спросите, а чё это мы ищем только часть адреса, когда выше нам выдало что чанк начинается с адреса 0x00018de8? Дело в выводе команды izz в r2. Она выводит относительные адреса начала "интересных блоков", и если вы её запустите, она будет указывать на начало типа нашего чанка, а не на адрес где сам чанк начинается. По этому, чтобы проверить более широкий спектр адресов я смотрю все значения от 0x00018de0 до 0x00018def.
В качестве вывода получаю данные о найденном значении:

То есть, наш чанк начинается с 2016 строки вывода izz с адреса 0x00018de7 количество отображаемых байт 12, количество байт всего 13 (это потому что мы закодировали символ разделения \0 как неотображаемый. Если бы там было тире или двоеточие, мы бы его видели и вывод был бы 13 13), далее видим кодировку ascii и текст который закодирован.
Имея номер строки начала интересующего нас сообщения (2016), получу его целиком:
r2 -qc 'izz' Cute_cat_text_chunk.png | sed -n '2016,2021p'
Что делает первый блок я уже объяснял, а вот sed -n '2016,2021p' просто отображает значение вывода команды izz с 2016 строки по 2021, а флаг -nпросто отключает вывод всех строк, как раз, предлагая, ввести интересующий нас диапазон. А буква p после конца интервала говорит о том что надо распечатать значения (print). При выполнении команды получаю:

Вот и наше закодированное сообщение.
Как вы могли понять, можно запихать свой чанк в любое место в файле, сделав его невидимым при простом просмотре изображения, но для упрощения процесса я положил его в конец.
Прячем текст на видном месте
Небольшое предисловие. Когда я писал статью и пытался прикрепить сюда примеры изображений с альфа слоем, всё что было сокрыто просто пропадало. Вероятно, дело в том, что альфа слой для png изображений тут съедается. По этому, попрактиковаться в поиске скрытых приколов на этих картинках у вас не выйдет, и в данном разделе мне пришлось прикреплять скриншоты, вместо реальных png файлов со спрятанным текстом.
Ещё один возможный способ скрыть текст на png картинке-спрятать его в альфа канале. Например, так:

Да, текст видно хорошо, но только потому что я сделал его не слишком прозрачным, но можно очень сильно скрыть его. Давайте покажу как я это провернул, и заодно покажу как такой текст можно проявить.
Стоит так же, немного объяснить, что же это за альфа канал? Тут всё максимально просто, это прозрачность. Как вы знаете у изображений в формате PNG есть три цветовых канала R - красный, G - зеленый, B - синий. А кроме них, есть четвертый канал, который отвечает не за цвет, а за прозрачность пикселей. Это и есть альфа канал. Он обозначается обозначается буквой A. Почему же мы говорим что у изображения только три канала? А потому что эти три канала обязательные, а альфа канал можно отключить, и тогда прозрачности у изображения не будет. И вот, манипулируя прозрачностью изображения в определенных местах, можно этой прозрачностью написать текст. Ниже объясню подробнее.
В первую очередь, создам текст, который буду добавлять на изображение:
convert -size 640x640 xc:"gray(96%)" \
-pointsize 40 \
-fill "gray(52%)" -gravity center \
-annotate +0+0 "У кота есть ушки" \
hiden_text.pngРазберем подробнее. Ранее я уже использовал инструмент convert для наложения текста на изображение. Тут суть та же, но добавилось пару опций.
xc:gray(96%) - нужна для создания однотонного холста, который будет наполнением фона. В моем случае я делаю его оттенком серого с яркостью 96%, то есть это почти что белый цвет.
-fill "gray(82%)" - задаю цвет текста. Так же, делаю его очень светлым.
Основная мыслю в том, чтобы наложить прозрачность на изображение. Форма прозрачности будет соответствовать форме текста. А уровень прозрачности будет равен разности между оттенком фона и оттенком текста.
Сейчас может стать понятнее:
convert Cute_cat.png \
\( hiden_text.png -alpha off \) \
-compose CopyOpacity -composite \
Cute_cat_alpha_htext.pngconvert Cute_cat.png - Беру базовое изображение, на которое буду накладывать маску текста. Использую его как фон для будущей операции.
\(hiden_text.png -alpha off\ ) - Беру в скобки второе изображение. В скобки оно взято, так как на его основе будет создано временное изображение, которое будет маской непрозрачности. И далее я отключаю альфа канал у маски. Я это делаю для того, чтобы в дальнейшем для маски наложения использовать не само изображение, а его яркость. Ну, то есть, я переношу на фото с котиком разность яркостей между фоном и самим текстом. И если ты хочешь сделать текст ещё более незаметным, просто уменьшай дельту. То есть бери не 52% а 94%, например. Тогда текст ты точно не сможешь заметить.
-compose CopyOpacity - Накладываю непрозрачность маски и копирую её в альфа канал внешнего изображение (котёнка). То есть по факту, я делаю часть изображения с котиком, на котором лежим маска, более прозрачным. Это как взять трафарет, и вместо того, чтобы закрасить по нему слова на стене, я вырезаю эти слова на стене по трафарету. Ну а в моём случае, я делаю изображение чуть прозрачнее в этих самых местах.
-composite- Просто применяю режим композиции вышеописанной команды для изображения.
И записываю результат в файл Cute_cat_alpha_htext.png. И вот что получится, если я попробую очень сильно скрыть текст (он тут есть, можете мне поверить):

Ну как, что-нибудь видно? А так?
convert Cute_cat_alpha_htext.png -alpha extract -auto-level alpha_boost.png
-alpha extract - извлекаю только альфа канал изображения в карту яркости. То есть получаю информацию о прозрачности каждого байта изображения.
-auto-level - берется минимум и максимум значений яркости с карты, минимальное значение сдвигается к чисто чёрному, максимальное - к чисто белому. А для всех значений между ними, выбирается усредненное значение. Но поскольку у меня было только два значения на моей цветовой карте, то я получаю вот такой результат:

Вот так можно скрывать что-то в альфа слое, и проявлять это что-то. Конечно, тут тема намного более обширная. Можно показать и как менять цветовую карту на цветных изображениях, накладывая прозрачность и так же, по их маске накидывать прозрачность на другой фон, но это уже тема для саморазвития и моего и вашего (если, конечно, у вас появится желание всё это повторить).
Немного CTF-а вам. Скрытый текст в цветовом градиенте
Разбираясь с этой темой, я наткнулся на пост в одном не безызвестном рессурсе, который отсылал на CTF 2014 года, в котором было задание на поиск сокрытого в картинке текста. Ссылку на статью я вам давать не буду, но источник на который они ссылались вот тут: https://ctfs.github.io/resources/topics/steganography/invisible-text/README.html. Там, в целом, много интересного много найти, но об этом, возможно, позже.
В том задании. Которое было дано в 2014 году, организаторы изменили цветовую карту изображения. Подобно тому как я выше демонстрировал изменение карты альфа канала png файла, они сделали то же самое, но с картой каналов RGB. Вместо того чтобы накладывать маску прозрачности, они наложили маску цветов. То есть, взяли какой-нибудь 8-битный цвет, например 7fffd4, и наложили на байты изображения маску, формирующую текст из этого цвета.
На самом деле, они создали фрагменты текста из масок разных цветов. Для получения ответа нужно было найти все цвета, которые формировали из себя маски, сложить их друг с другом и получить флаг.
В данном разделе я не буду показывать как реализовать данный метод, так как, буду честен, не практиковал его, а просто тырить код из StackOverFlow это тупо. Но если у кого-то из читающих данную статью возникнет желание подробнее ознакомиться с решением вышеописанного задания, оно есть на гите, с работающим кодом, и примерами изображений: https://github.com/ctfs/write-ups-2014/tree/master/plaid-ctf-2014/doge-stege
Exiftool для просмотра/добавления метаданных
Все файлы так или иначе хранят в себе какую-либо информацию, помимо той, что на поверхности. Это может быть временем создания или редактирования, размер, имя владельца, модель устройства на котором файл был создан, геолокация и много чего ещё. Конечно, многие из этих данных не всегда пресутсвуют у файла. Но если они имеются - вытащить их очень полезно. Для извлечения метаданных файла существует множество инструментов. Один из таких это exiftool.
Запущу его и посмотрю что смогу подцепить из изображения с милым котиком:

Как видно, ничего особо интересного. В этом файле нет. Стандартная png-шка.
Но можно посмотреть что-то из того, где я прятал текст. Например, изображение из позапрошлого пункта:
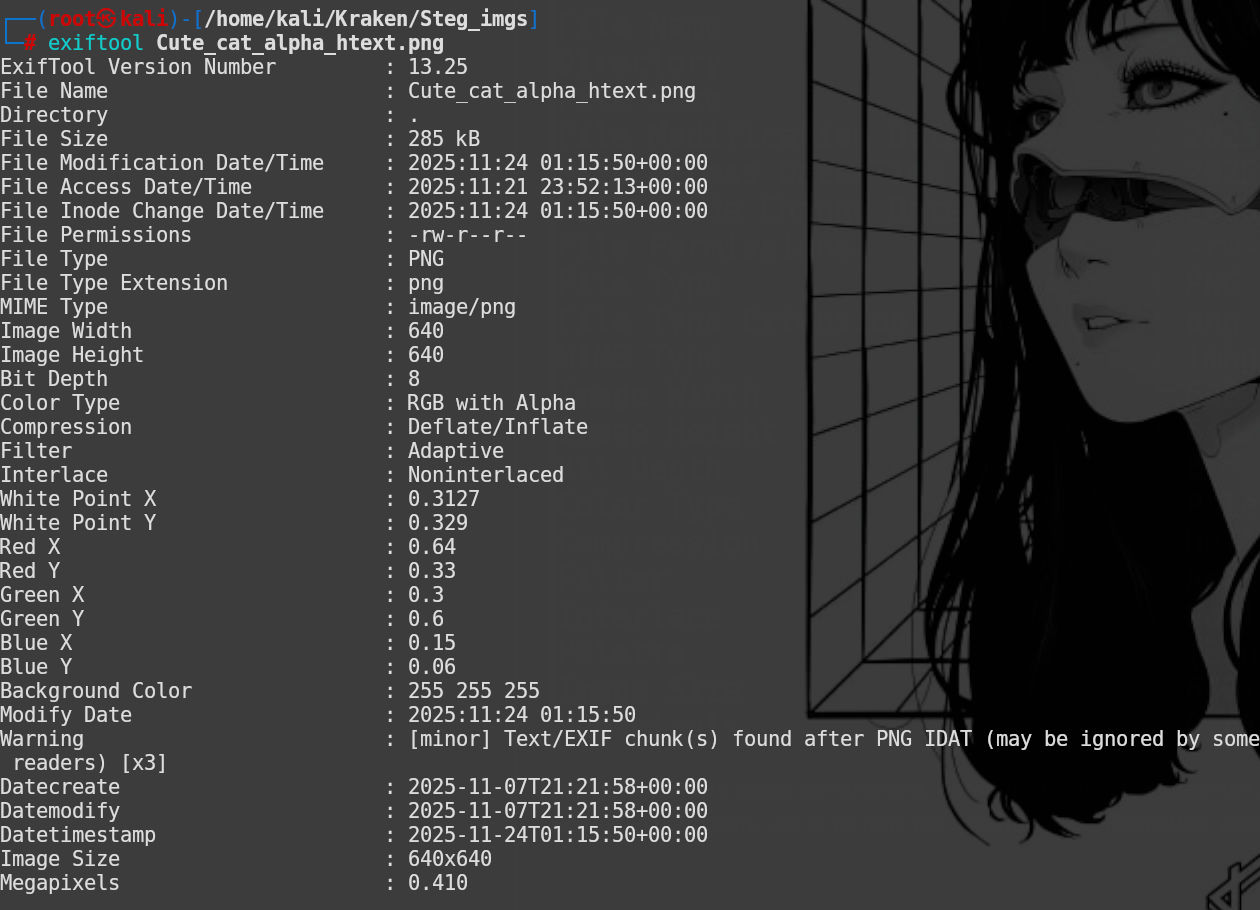
О, а вот тут мы видим что что-то делали с цветовой схемой, так как фон у нас белый: Background Collor: 255 255 255, а так же Color Type: RGB with Alpha - говорит о наличии альфа слоя в котором может что-то прятаться. А так же, мы видим предупреждение о том что какие-то текстовые чанки (tEXt/iTXt или EXIF) идут после блока IDAT, который должен завершать файл. Это не ломает изображение, но эти чанки не видны в метаданных из-за такого положения. Отличный повод сходить в бинарник и посмотреть что хранится в этих чанках.
Exiftool хорош ещё и тем, что позволяет добавлять свои метаданные, но только на существующие в самом инструменте тэги.
Так, например, если я хочу добавить комментарий к файлу, я сделаю это так:
exiftool -overwrite_original -EXIF:ImageDescription="Описание красивого котика" -PNG:Comment="Тут очень милый котёнок" Cute_cat.png
-overwrite_original - указываю что нужно записать указанную информацию поверх текущего файла. В противном случае, exiftool создаст новый файл (выкинув ошибку, если ты заранее не укажешь имя итогового файла)
-EXIF Указываю в какой блок (или, что одно и то же, чанк) зансить данные. Конкретно в этом чанке может храниться разнообразная информация, от модели камеры, до геолокации и использованного ПО. И данные эти можно добавить.
ImageDescription="Описание красивого котика" - Для тэга ImageDescription в чанке EXIF я добавляю описание, тут всё просто. Но стоит понимать что у каждого чанка свои тэги и их очень много.
PNG:Comment="Тут очень милый котёнок" image.png - делаю то же что и ранее, но для тэга Commentв чанке PNGдобавляю текст.
По итогу, вижу ранее не существующие блоки в метаданных моего файла с котиком:

А самое приятное, что метаданные можно менять. Например, изменить название камеры, с которой был произведён снимок, сменить время создания или редактирования документа (тебя попросили сделать презентацию неделю назад, а ты сделал её час назад, и чтобы не спалиться можно изменить метаданные), изменить геолокации фото. В общем, очень полезная опция. Для этого, я добавил геолокации в файл с котиком:
exiftool Cute_cat.png -overwrite_original \
-GPSLatitude=55.751507 -GPSLongitude=37.618583 \
-GPSLatitudeRef=N -GPSLongitudeRef=EА чтобы изменить координаты места, где было сделано фото необходимо просто переписать эти значения:
exiftool Cute_cat.png -overwrite_original \
-GPSLatitude=55.797564 -GPSLongitude=49.106567И при просмотре метаданных файла получаю такой вывод:

Удобный и много функциональный инструмент, но, поскольку, тут я хотел лишь рассказать как прятать информацию и находить её, подробнее о нем вам придётся почитать самостоятельно, если будет желание.
В данном тексте я лишь хотел собрать несколько методов сокрытия данных в изображении и хоть сколь-нибудь их законспектировать, попутно самостоятельно в них разбираясь. Надеюсь, кому-нибудь, эта статья окажется полезна. В конце концов, не все CTF ещё решены, возможно, при поиске информации, вы наткнетесь на эту кучу моих мыслей и узнаете что-то полезное.
Больше практики — в Академии Кракен (Kraken Academy). Подписывайся на наш Telegram-канал.
Рекомендуемые публикации

Термины ИБ - от первого дня до первого инцидента
Читать полностью →
Расследование HR - Куда на самом деле пропадают ваши резюме и как заставить их засветиться в ИБ
Читать полностью →